China is Building 89 Shercos in the Coming Years
Yesterday I posted about how India is building a lot of coal-fired power plants. These power plants would have a generation capability equal to building the Sherburne County (Sherco) coal-fired power plant, Minnesota’s largest electricity generator, 42 times.
It turns out that China, not to be outdone, is going to build the equivalent of 89 Shercos to provide affordable, around-the-clock energy for millions of people.
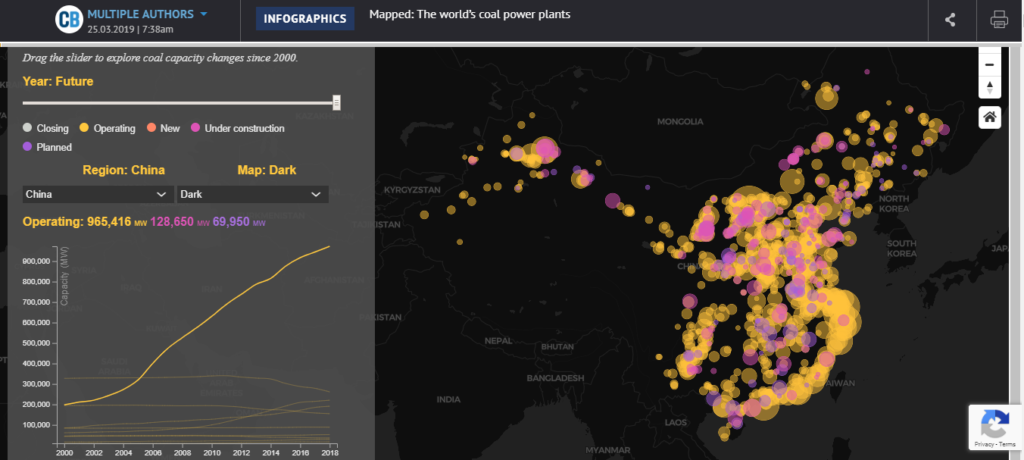
This is good news for Chinese citizens, who use 63 percent less electricity, on a per-capita basis, than people living in the United States, but it could mean bad news for energy intensive industries like mining and manufacturing in Minnesota.
China is the third-largest producer of iron ore in the world, producing 348 million metric tonnes in 2016. In contrast, the United States was ranked 9th, producing just 42 million metric tonnes that year, or just 12 percent of China’s output, with most of our output coming from Minnesota.
However, mining is enormously energy intensive. In fact, iron mines and paper mills in Minnesota consumed 8 percent of all the electricity used in the state in 2016. If Minnesota enacts energy policy that forces the Clay Boswell coal plants (owned by Minnesota Power) to close down before the end of their useful lifetimes, it will increase energy costs at Minnesota mines and put them at a competitive disadvantage relative to mines in China.
Closing our coal plants would also harm manufacturing facilities around the state by driving up the cost of energy. American Experiment’s research shows even enacting a 50 percent renewable energy mandate would cost industrial electricity consumers an additional $93 million per year. In some cases, this policy could make it too expensive to operate in Minnesota, incentivizing companies to move to other states with lower energy costs, or perhaps even to China.
Putting two of Minnesota’s most important industries at risk to reduce carbon dioxide emissions at a time when China is set to build the equivalent of 89 Sherco plants, thus increasing their emissions, makes no sense. This is why it is a very good thing that proposals to force Minnesota’s electricity sector to be 100 percent “carbon free” by 2050 supported by Governor Walz and DFL members of the House of Representatives were shot down by the Senate in the recently-concluded legislative session.